| | PROGRAMACIÓN
CONCURRENTE |
“El medio es el mensaje” (Marshall McLuhan)
Concurrencia vs. Paralelismo
En primer lugar conviene distinguir entre procesos concurrentes y paralelos:
- Varios procesos son concurrentes (en un cierto momento) si se están ejecutando simultáneamente.
- Varios procesos son paralelos cuando comienzan a ejecutarse a la vez.
Los procesos paralelos son concurrentes mientras se están ejecutando. A medida que los procesos van finalizando, la concurrencia (en número de procesos) va disminuyendo hasta que solo queda un proceso o ninguno.
Los procesos concurrentes interactúan entre ellos mientras se están ejecutando. Es por ello que el número de posibles rutas de ejecución puede ser muy grande e incluso el resultado final ser indeterminado.
Un sistema concurrente es un conjunto de procesos que colaboran (para lograr un objetivo común) o compiten entre sí porque cada proceso persigue un objetivo particular.
Tipos de procesos
Los procesos pueden ser de dos tipos:
- Estáticos. Son los creados explícitamente por el programador.
- Dinámicos. Son procesos creados por otros procesos durante la ejecución de un sistema.
Un sistema cerrado es el que todos los procesos son estáticos. Un sistema abierto es el que tiene al menos un proceso dinámico. En un sistema abierto, el número de de procesos en ejecución varía con el tiempo.
Justificación de la concurrencia
El estudio de la concurrencia se justifica por sus grandes ventajas:
- Resuelve problemas de naturaleza concurrente como: sistemas operativos, sistemas de control, sistemas cliente/servidor, sistemas de gestión de bases de datos, navegadores web, correo electrónico, chats, etc. En general, los sistemas que dan servicio a usuarios y programas están diseñados para funcionar indefinidamente.
- Mejora el rendimiento de la ejecución de un sistema, pues los procesos pueden cooperar entre sí para repartirse la carga de trabajo.
- Proporciona un modelo más flexible y natural de concebir las aplicaciones.
- Facilita el desarrolla de sistemas complejos.
- Permite optimizar el uso de los recursos.
Implementación de la programación concurrente
La programación de la concurrencia (también llama ingeniería de la concurrencia) se ha abordado tradicionalmente de dos formas:
- Mediante un lenguaje que soporte la concurrencia, como Ada o Java.
- Usando los recursos software de concurrencia del sistema operativo. Son utilizables desde varios lenguajes.
En general, se suele ocultar al programador la complejidad subyacente a la concurrencia.
Modelos teóricos de sistemas concurrentes
Existen muchos modelos teóricos de sistemas concurrentes. Los más destacados son:
- Redes de Petri.
Son grafos orientados acíclicos con dos clases de nodos: lugares y transiciones. Los arcos unen un lugar con una transición o viceversa. Las redes de Petri fue uno de los primeros modelos (data de los años 1960s).
- Álgebra de procesos.
Es una familia de enfoques que suministran herramientas para una descripción de alto nivel de las comunicaciones, interacciones y sincronización entre procesos. Las comunicaciones se realizan mediante mensajes vía canales. El álgebra se basa en un pequeño conjunto de primitivas y unos operadores que permiten combinar esas primitivas. Un ejemplo de álgebra de procesos es CSP (Communicating Sequential Processes), presentado por Hoare en 1978.
- SCOOP (Simple Concurrent Object Oriented Programming).
Es un modelo de concurrencia diseñado para el lenguaje Eiffel, concebido por el creador de Eiffel (Bertrand Meyer). Su objetivo es facilitar el desarrollo de programas concurrentes con casi el mismo esfuerzo adicional que los programas no concurrentes (centralizados y distribuidos).
La gran variedad de modelos teóricos ha motivado a algunos investigadores a buscar una posible unificación y un estándar que hoy día no existe. Actualmente la teoría de la concurrencia es un área de investigación muy activa.
Tipos de comunicaciones entre procesos
Las comunicaciones entre procesos pueden ser de dos tipos:
- Asíncronas.
Un proceso fuente p1 envía información a otro proceso destino p2, y p1 no espera la respuesta de p2. Solo se utiliza una primitiva: Send (enviar).
Por ejemplo, los rastreadores de Internet realizan peticiones tipo http para obtener páginas. Las respuestas que van llegando las acumula para luego analizarlas. El proceso no es determinista porque las respuestas no se reciben necesariamente en el mismo orden que las peticiones.
- Síncronas.
Un proceso fuente p1 envía información a otro proceso p2, y p1 espera la respuesta de p2 para poder continuar el proceso. Se utilizan dos primitivas: Send (enviar) y Wait (esperar respuesta).
Ejemplos de comunicaciones síncronas son en general los sistemas cliente-servidor como: servidores web, servidores de bases de datos, servidores de transacciones o peticiones asociadas a clics de ratón del usuario en el IGU (interfaz gráfico de usuario), etc.
En ambos casos, la información consta de datos y la identificación (o señal) del proceso fuente. En el caso de las comunicaciones síncronas, las señales sirven para la sincronización.
Mecanismos de comunicación entre procesos concurrentes
Hay dos, principalmente:
- El paso de mensajes entre procesos.
- La vía de la memoria común entre procesos.
En ambos casos, la comunicación puede ser síncrona o asíncrona.
En los sistemas centralizados se comparte una memoria común (entorno) y los procesos se pueden comunicar indirectamente a través de esta memoria común. En los sistemas distribuidos no hay memoria compartida, hay varios entornos, y la comunicación se tiene que implementar mediante paso de mensajes.
La utilización de los eventos es la forma de gestión de la concurrencia que se ha demostrado más eficaz.
Compartición de recursos entre procesos
Una implementación posible puede ser utilizando un mecanismo tipo cola de espera:
- El proceso que quiere acceder al recurso se pone en una cola de espera.
- El proceso se detiene esperando el acceso al recurso (en espera activa).
- La cola es atendida siguiente una política FIFO (First In, First Out). El proceso que atiende la cola le da acceso al recurso.
- El proceso sale de la espera activa y el proceso continúa su ejecución normal.
Entornos de ejecución
Existen tres entornos de ejecución:
- Un sistema monoprocesador con multiprogramación.
En la multiprogramación varios procesos se alojan en la memoria principal y son ejecutados por una sola CPU.
- Un sistema multiprocesador con memoria compartida.
Cada procesador atiende a un proceso.
- Un sistema distribuido.
En este caso no hay una memoria compartida, por lo que la comunicación debe hacer mediante mensajes.
Implementación de sistemas concurrentes
La concurrencia de procesos exige un mecanismo gestor o un sistema operativo que distribuya los recursos disponibles sobre los procesos. Los más destacados son:
- Time slicing (rodajas de tiempo).
El tiempo de la única CPU se divide en n intervalos iguales (n procesos) y el sistema va asignando los recursos de manera cíclica entre los procesos. Cada proceso tiene la “impresión” de que se está ejecutando en una máquina real dedicada a ese proceso. Se dice de que cada proceso es atendido por una “máquina virtual”. Es un pseudoparalelismo, pues no hay realmente paralelismo físico.
- Threads (hebras o hilos) de ejecución.
Un hilo es la unidad de procesamiento más pequeña que puede ser gestionada por un sistema operativo. Los hilos hacen posible ejecutar un sistema de forma concurrente. Un hilo es simplemente una tarea que puede ser ejecutada al mismo tiempo que otra tarea. Cada hilo o proceso se ejecuta en su propio procesador virtual. Los distintos hilos de ejecución comparten los recursos del sistema. Un proceso se compone de varios hilos de ejecución independientes. Los hilos utilizan la memoria para comunicarse entre sí, pero cada hilo utiliza un espacio de direcciones virtual.
- Sistema fork.
En este caso no se utilizan hilos. La memoria se divide entre los diferentes procesos. Es un sistema más seguro que los hilos.
Especificación en MENTAL
Abordamos el tema de la concurrencia desde un punto de vista teórico, sin hacer referencia a posibles implementaciones concretas (procesadores, espacios de memoria, etc.). La concurrencia teórica o mental (no física) es más general que la física, pues el diseño de los programas no están condicionados por los recursos computacionales disponibles.
MENTAL, al contrario que otros lenguajes, no necesita ningún recurso teórico especial para el diseño de programas concurrentes. Bastan las primitivas del lenguaje. Si necesitara recursos especiales adicionales, no sería un lenguaje universal. Con MENTAL, la programación de la concurrencia es más sencilla e intuitiva. Las interrupciones, las comunicaciones y la sincronización de procesos se expresa en un lenguaje de alto nivel.
MENTAL es el modelo natural de concurrencia. Es el modelo “madre” del que emergen todos los demás modelos particulares.
En MENTAL no se distingue entre proceso y tarea porque el mecanismo en ambos casos es idéntico: cuando un proceso se divide en varias tareas o cuando un sistema se divide en varios procesos. A partir de ahora utilizaremos solo los términos de “sistema” y de “proceso”.
Comunicación entre procesos
La comunicación entre procesos se realiza a través del espacio abstracto. Es el mecanismo más simple de comunicación. La sincronización se realiza mediante eventos. Un proceso deposita un valor en una variable y una expresión genérica activa otro proceso cuando la variable toma un valor o valores determinados.
Ejemplos de sincronización de procesos
- Sincronización pura.
Queremos sincronizar dos procesos p1 y p2, de tal manera que comiencen a ejecutarse a la vez. Para ello creamos una variable s (de “sincronización”), de tal manera que si s=1, p1 y p2 comiencen a ejecutarse en paralelo:
⟨( s=1 → (s=0 {p1 p2} )⟩
La restauración de s es importante, pues si no se hiciera, se estaría arrancando en todo momento la ejecución paralela de los dos procesos. Esta notación tiene la ventaja de que se puede arrancar la ejecución de los dos procesos repetidas veces (cada vez que hagamos s=1).
- Esperas pasiva y activa de un proceso.
Un proceso está en espera pasiva si está en espera a que lo invoquen explícitamente para que se ejecute.
Un proceso está en espera activa si, en todo momento, está comprobando si se verifica una cierta condición para comenzar a ejecutarse. La expresión a aplicar es la siguiente:
⟨( condición → proceso )⟩
Por ejemplo, un proceso A debe esperar a que el proceso B finalice para poder continuar su ejecución. Si la tarea B indica que ha finalizado mediante b=1, y llamamos A1 a la tarea previa y A2 la continuación de la tarea A cuando termina B, tenemos un bucle de espera en el código que separa A1 y A2:
(espera = (espera ←' b=1 → A2))
Expresiones paralelas
Son aquellas que aparecen asociadas a la primitiva “grupo paralelo” o conjunto. Ejemplos:
- Evaluaciones o ejecuciones paralelas de tres expresiones.
- Condiciones paralelas.
- Sumas paralelas.
La expresión serie (no concurrente) a+b+c+d se puede expresar como
({(s1 = a+b) (s2 = c+d)} (s1+s2)¡)!
En este caso no es posible la concurrencia completa, debido a la propia naturaleza de la operación.
- Sustitución relativa paralela.
(a a+4 b b+8)/{a=1 b=2} ev. (1 5 2 10)
Estructuras de procesos
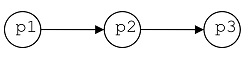
Un conjunto de procesos que se ejecutan en serie se especifica mediante una expresión serie (secuencia). Por ejemplo,
En donde primero se ejecuta p1; cuando termina, se empieza a ejecutar p2; etc.
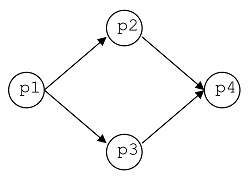
Un conjunto de procesos que se ejecutan en paralelo se especifica mediante una expresión paralela (conjunto). Por ejemplo,
En donde los procesos p1, p2, p3 y p4 comienzan a ejecutarse a la vez.
Mediante estas dos primitivas (secuencia y conjunto) y sus combinaciones podemos especificar diferentes estructuras de procesos. Ejemplos:
(q1 {p1 p2 p3} q2)
Primero se ejecuta q1; cuando termina, se ejecutan en paralelo los procesos p1, p2 y p3; cuando estos tres últimos procesos finalizan, entonces comienza a ejecutarse q2.
{p1 {p21 p22} p3}
Hay sincronicidad inicial entre los 4 procesos, por lo que esta expresión es equivalente (únicamente desde el punto de vista concurrente) a {p1 p21 p22 p3}.
Interacciones entre procesos
Un proceso p1 puede interaccionar con otro proceso p2 de las siguientes formas:
- Afectando a su flujo de ejecución mediante las acciones:
Iniciar proceso p2: p2!
Finalizar proceso p2: p2¡
Parar proceso p2: (■ p2)
Continuar proceso p2: (▶ p2)
- Modificando su código de forma dinámica.
- Actualizando expresiones compartidas (normalmente, variables).
Observaciones:
- La operación “Parar”
(■) es una primitiva de MENTAL. Su contraria (■'= ▶) es “Continuar”.
- Si
p es un proceso parado, ■p no produce ningún efecto.
- Si
p es un proceso en ejecución, &9654;p no produce ningún efecto.
- Puede haber, evidentemente, interacción mutua entre los dos procesos.
- Cuando dos procesos no interactúan entre sí de ninguna forma, se les denomina “disjuntos”.
Un proceso p1 puede detener a otro proceso p2 de forma directa. Una situación típica se produce cuando el proceso p1 desea realizar, a partir de cierto momento, cierta tarea sin ser “molestado” o afectado por el otro proceso. Para ello, lo que hace es:
- Detener el proceso
p2: (■ p2).
- Ejecutar el proceso
p1.
- Reanudar el proceso
p2: (▶ p2).
Es posible conocer el estado de un proceso asignando valores a variables de estado. Por ejemplo, al comenzar el proceso p, hacemos por ejemplo (ejec(p) = 1) y al final del proceso se hace (ejec(p) = 0). Preguntando por esta variable podemos conocer su estado: en ejecución o no.
Diseño de sistemas de procesos concurrentes
Se realiza mediante diagramas de precedencia, en los que se utiliza la representación
para indicar que p1 se debe ejecutar antes que p2. Se codifica (p1 p2).
Cuando dos procesos aparecen en la misma vertical, indican paralelismo. Se codifica {p1 p2}.
El diseño va a depender de la granularidad (grande o pequeña) de los procesos.
Ejemplos:
- El diagrama
se puede representar mediante la secuencia (p1 p2 p3)
- El diagrama
En donde los procesos situados en la misma vertical se ejecutan en paralelo. Se puede representar mediante (p1 {p2 p3} p4)
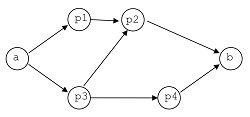
- El diagrama
lo podemos expresar mediante una combinación de expresiones serie y paralela, junto con expresiones genéricas que establecen las condiciones de prioridad de ejecución de los procesos:
(q1 =: (k1=0 p1 k1=1))
(q2 =: (k2=0 p2 k2=1))
(q3 =: (k3=0 p3 k3=1))
(q4 =: (k4=0 p4 k4=1))
// Ejecutar a, y q1 y q3 en paralelo
(a {q1 q3})
// Si p3 ha finalizado, ejecutar p4
⟨( k3=1 → (k3=0 q4 )⟩
// Si han finalizado p2 y p4, ejecutar b
⟨( (k2=1 k4=1) → (k2=0 k4=0 b )⟩
La flecha que va de p3 a p2 es innecesaria, puesto que p2 se ejecutará cuando hayan acabado p1 y p3.
Ejemplo: cálculo de π
Se utiliza la fórmula de Leibniz (n es el nro. de términos);
π = 4*(1 − 1/3 1/5 − 1/7 + ... + 1/(2*n − 1)
Versión serie:
⟨( pi(n) = ( s=0 // suma de los términos de la serie
i=0 // número del término de la serie
(signo = −1) // signo inicial del término
( (signo = −signo)
(s = s + signo÷(2.*i − 1)
(i = i+1) )★n )
¡(4*s) )! )⟩
Versión paralela:
⟨( pi(n) = 4*(+ ({[(−1)^[1…n]+1] * 1.÷(2*⌊2…n+1⌋] )⟩
Esta version solo utiliza una variable, que es el parámetro n.
Variables en procesos
Para evitar que se confundan las variables del mismo nombre y pertenecientes a procesos distintos, una posible solución es utilizar la notación x(p), donde x es la variable del proceso p.
Cuando varios procesos pueden acceder concurrentemente a un recurso compartido (por ejemplo, una variable), se plantea el problema de que solo un proceso cada vez debe acceder a dicho recurso. Es lo que se llama “exclusión mutua”.
Se han propuesto numerosas soluciones a este problema. Lo más recomendable es realizar un procedimiento genérico parametrizado que resuelva el problema de forma segura para cualquier proceso y cualquier variable.
Un proceso necesita actualizar el dato (valor) de la variable x y otro proceso también intenta hacer lo mismo. El primer proceso que vaya a realizar la actualización debe bloquear el código de actualización y desbloquearlo tras la actualización.
⟨( acceso(x° dato) =
(bloqueo(x°) := 0) // valor inicial (desbloqueado)
(z° = (bloqueo(x°) = 1) → z) // esperar a que se desbloquee
(bloqueo(x°) = 1) // bloquear
(x° = dato) // actualizar variable x
(bloqueo(x°) = 0) // desbloquear
)⟩
Ejemplo: acceso(v° 23)
Suponemos que es imposible (a nivel teórico) que varios procesos ejecuten simultáneamente este código, pues la simultaneidad solo es posible realizarla mediante una expresión paralela.
Un ejemplo de variable compartida es el siguiente. Un recinto tiene varias entradas, con un torno en cada una de ellas, que cuenta el número de visitantes que entran. Hay un proceso de conteo por cada entrada. El problema es saber en todo momento el número total de visitantes que han entrado en el recinto. Si todos los procesos comparten la misma memoria, la variable que totaliza el número de visitantes en todo momento es
Siendo ni el contador del torno i y k el número de entradas. Esta expresión, al ser genérica, siempre se está evaluando, por lo que la solución es extremadamente simple.
Adenda
OpenMP (open Multiprocessor)
Es el estándar de facto para programación paralela en sistemas de memoria compartida. Es un API para un entorno de programación multiproceso con compartición de memoria. Consta de un conjunto de rutinas, directivas de compilación y variables de entorno. Suministra un interfaz simple y flexible para el desarrollo de aplicaciones paralelas. OpenMP ha sido implementado en muchos compiladores y diversos sistemas operativos, incluyendo Windows y Unix.
OpenMP se basa en el modelo fork-join, un modelo que proviene de los sistemas Unix, donde una tarea grande se subdivide en varias subtareas (o hilos) más pequeñas que se ejecutan en paralelo, para luego “recolectar” los resultados obtenidos de cada tarea y unirlos en un único resultado final.
Aparición de bloqueos en procesos
En programación concurrente pueden aparecer bloqueos como consecuencia de problemas imprevistos:
- Interbloqueo pasivo (deadlock).
Todos los procesos están esperando que ocurra un evento que nunca se producirá.
- Interbloqueo activo (livelock).
Los procesos ejecutan instrucciones, pero no hay ningún progreso efectivo.
- Inanición (starvation).
Se produce cuando un proceso espera indefinidamente a que le proporcionen recursos.
Una breve historia de los lenguajes de programación concurrente
- Inicialmente la programación concurrente se realizaba en lenguaje ensamblador, a bajo nivel.
- En 1972 apareció el primer lenguaje de alto nivel que soportaba concurrencia: Concurrent Pascal [Brinch-Hansen, 1975]. Se creó como herramienta de diseño e implementación de sistemas operativos.
- En 1978 Hoare desarrolló CSP (Communication Sequential Process) para sistemas distribuidos.
- En 1980-81, Niklaus Wirth desarrolló Modula-2, descendiente directo de Pascal y Modula.
- En 1980 el lenguaje Ada incorporaba concurrencia en las sentencias del lenguaje.
- En 1981 apareció Concurrent Euclid, orientado al desarrollo de software concurrente fiable y eficiente.
- Java, lenguaje reciente orientado a objetos, soporta la programación concurrente mediante primitivas específicas.
Bibliografía
- Arnold, André; Beauquier, Joffroy; Bérard, Béatrice; Rozoy, Brigitte. Programas paralelos. Modelos y Validación. Paraninfo, 1994.
- Birrell, Andrew D. An Introduction to Programming with Threads. Digital Systems Research Center, 1989. Disponible online.
- Brinch-Hausen, P. The programming language Concurrent Pascal. IEEE Transaction on Software Engineering, 1 (2): 199-207, 1975.
- Drake, José María. Computación Concurrente. Internet.
- Palma Méndez, José Tomás; Garrido Carrera, Mª del Carmen; Sánchez Figueroa, Fernando; Quesada Arencibia, Alexis. Programación Concurrente. Thomson, 2003.
- Pérez Martínez, Jorge E. Programación concurrente. Editorial Rueda, S.L., 1990.
- Tanenbaum, Andrew S. Operating Systems (Design & Implementation). Prentice-Hall, 1987.